线段树小结
本文主要是对线段树在序列上的应用的简单讲解,并不涉及复杂的线段树应用。
从分治说起
众所周知,分治是一种常见的算法。序列上的分治通常是这种形式: 1
2
3
4
5result solve(int l, int r) {
int mid = (l + r) >> 1;
auto resl = solve(l, mid), resr = solve(mid + 1, r);
return merge(resl, resr)
}solve 的复杂度,因此要考虑优化。
首先,最简单的想法就是记忆化,然而问题在于,只需要稍微改变一下一开始询问的 l,r,最后调用的结果就会截然不同,永不上缓存的结果。因此,我们需要想方法增加重叠的子问题。
假如 merge 的实现分割点位置无关的话,将区间如何分成两段其实并不重要。我们可以先调用一次 solve(1,n),把递归调用的 solve 的答案记录下来,然后使用保存下来的答案将对应的区间拼出来。如下图所示。 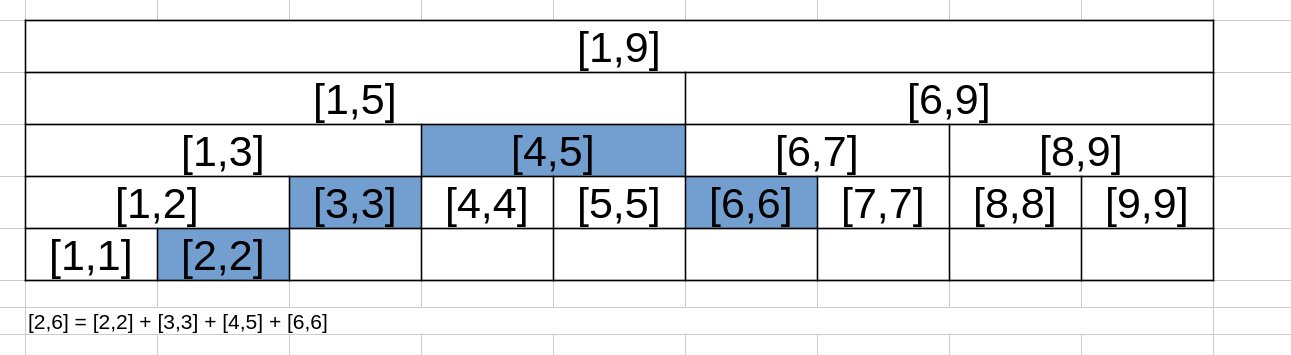 如上图蓝色区域所示,区间
如上图蓝色区域所示,区间
TIP 实现
对于二叉树的存储,我们可以开一个数组 a,每个结点 a[i] 对应的左右孩子分别对应 a[i*2] 和 a[i*2+1]。虽然线段树的结点个数最多只有
这里是一个参考的区间 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25struct node {
ll l, r;
tag t; //稍后解释
ll maxn;
bool leaf() { return l == r; }
};
ll lc(ll x) { return 2 * x; }
ll rc(ll x) { return 2 * x + 1; }
ll query(ll p, ll l, ll r) {
if (tree[p].leaf()) {
return tree[p].maxn;
}
ll mid = (tree[p].l + tree[p].r) >> 1;
ll res = -0x3f3f3f3f3f3f3f3f;
spread(p); //稍后解释
if (l <= mid) {
res = max(query(lc(p), l, r), res);
}
if (mid + 1 <= r) {
res = max(query(rc(p), l, r), res);
}
return res;
}
修改
显然线段树的功能不止于此。它还可以很方便地支持修改。
单点修改
注意到加入修改序列上的一个点 merge 即可。因此实际上我们仅仅是调用了 merge 而已。假设 merge 是
区间修改
显然不可能对于区间中的每个点都修改。参考询问,将区间分成
TIP 实现
更新时,如果子节点原本就有标记,需要将标记合并,而不是简单的替换(尽管对于某些题目这两个操作是等价的)。对于标记十分复杂的情况,可以考虑定义一个结构体 tag,重载 operator+ 来计算一个 tag 对另一个 tag 的影响。同理,如果合并两个子节点的信息极为复杂,可以定义一个 update 函数来更新结点信息。另外,如果实现了区间修改,就没必要实现单点修改了。
1 | |
动态开点线段树
当维护的区间过于庞大时(例如,需要在 new_node 函数来进行。 1
2
3
4
5
6
7node tree[N*60];// 此处大小需要自行计算。
ll cnt = 0;
//使用时:
tree[p].lc = cnt++;
tree[tree[p].lc] = node();
//...其他初始化操作
TIP 实现
应当避免使用 std::vector 来实现动态开点线段树。原因是 std::vector 的 push_back 会使迭代器失效,在递归过程中造成一系列问题。
参考题目
这些题目是用于加深理解的。限于篇幅,并不能一一讲解,可以参考对应题目的题解。
- 洛谷 P1253 需要厘清如何合并标记。
- 洛谷 P4198 虽然在讲解中我们都假设
merge或者update是的,但实际上并非如此,只要最后的复杂度可以接受(具体题目具体分析)都可以使用。这题可以先考虑如何使用分治实现(如何合并两个区间的信息),在借助线段树的结构维护信息,优化复杂度。此外,一道题需要维护的信息不止一种,因此查询也可以有很多种。 - 洛谷 P7453 这道题的前置知识是矩阵。更加复杂的更新与标记下传。
可持久化线段树
可持久化线段树可以支持在线的修改在历史版本上的修改,查询。最简单的方法就是每个修改新开一颗树,显然时空双飞。
正如我们之前提到的,单点修改最多影响 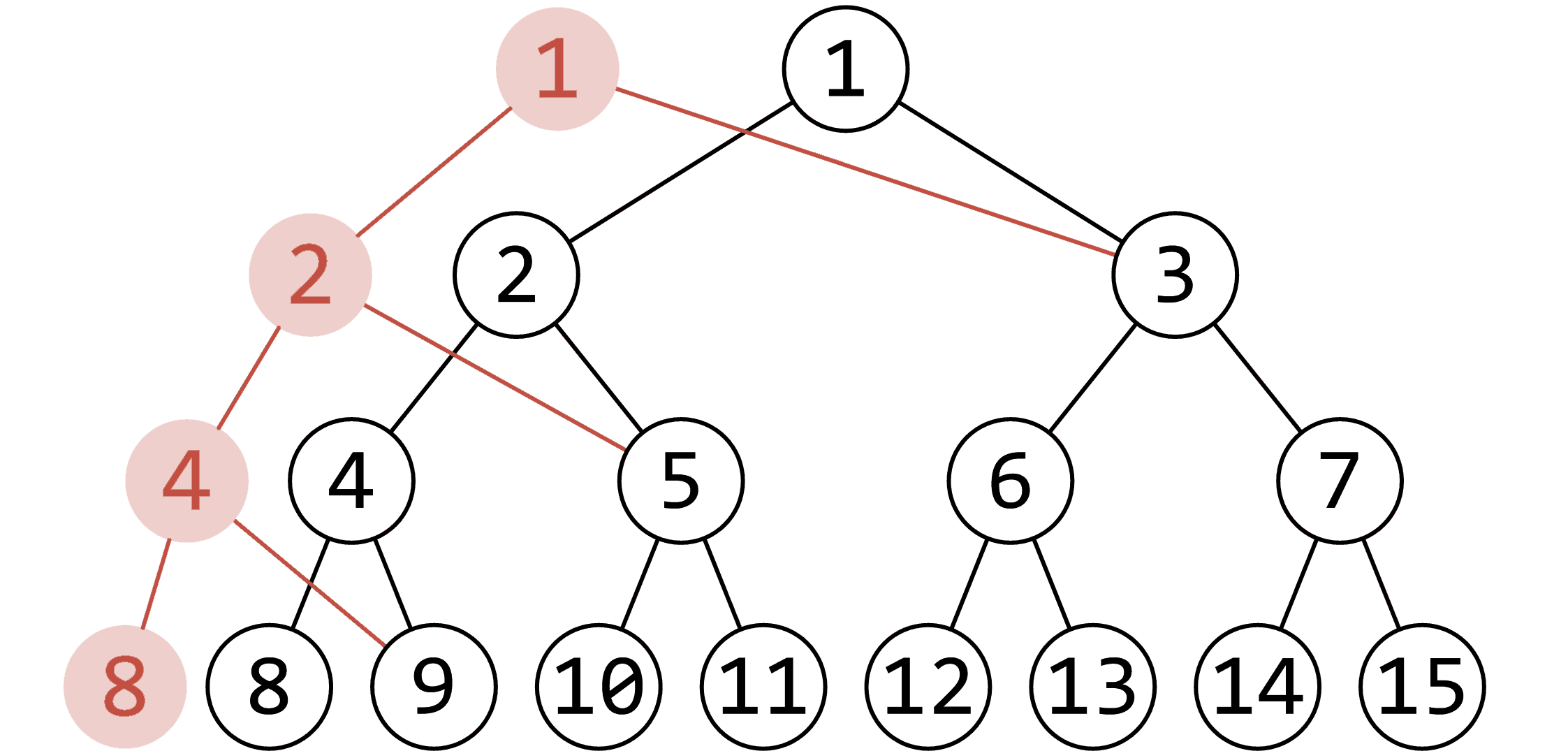 单次修改的时间复杂度仍是
单次修改的时间复杂度仍是
可持久化线段树的一个常见的用法是对于
洛谷 P1962 改。 给定一个长度为
考虑就是扫描一遍数组,记录每个数上次出现的位置。假设数字
接下来,将这个
线段树二分
注意到线段树将区间分为左右两个的方式很适合二分。线段数二分就是在线段树上二分。具体的方法是首先检查左子节点的信息是否符合要求,如果是则递归到左子节点,否则递归到右子节点。
例如,我们要查询一颗权值线段树上第
- 查询左子节点数的总数
。 ,查询左子节点第 大的数。 ,查询右子节点第 大的数。
线段树二分通常与可持久化线段树一起来对区间进行询问。比方说下面这个例题:求区间
考虑一个数没有在一个区间
- 查询左子节点的最小值
。 ,说明左子节点至少有一个数没有在区间内出现,向左递归。 - 否则,说明左子节点的左右数都出现了,向右侧递归。
单次复杂度
线段树分治
标记永久化
如果修改之间支持交换律,那么可以不下传标记,在询问时统计经过的标记对结果的影响。这个技巧在部分题目中相当有用。
例如:AtCoder AT_abc342_g。需要实现区间取 mutiset(注意标记可能一样),查询的时候对于路径上的节点上的 mutiset 中的最大值取 erase 即可。
线段树分治
接下来讲解线段树分治。考虑标记永久化,如果你需要在最后一次性询问每个下标该怎么办?要知道,并不是每道题目都可以只考虑节点上标记的其中一种一个造成的影响,有时你必须考虑所有标记(稍后你会看到)。考虑你查询完下标为
这就是线段树分治,一种离线算法,可以解决此类问题:动态插入,删除元素,询问一个问题(所有询问都相同)。线段树分治可以将插入和删除操作转化为插入和撤销操作。通常来说撤销操作都是较好实现的,只需要记录操作前的数据,撤销时还原即可。
线段树分治不仅可以运用在序列上,也可以运用在其他维度,比如时间。这也是线段树分治较为常见的用途。通过将插入和删除转化为时间上存在的区间,在线段树对应的节点上打上标记,最后一次 DFS 求出每个时间上的结果。
以洛谷 P5787为例,需要维护一个扩展域并查集来维护二分图。对于每条边,记录其存在时间
WARNING 实现
对于需要撤销的并查集,不能使用路径压缩,复杂度是假的。
线段树合并与分裂
权值线段树(通常是动态开点)支持合并与分裂。先说合并。
线段树合并
线段树合并的过程是这样的。
- 同步遍历两颗线段树。
- 如果只有一颗线段树上有这个节点,那么就直接将这个节点接在合并后的线段树上。
- 如果两个都有,就递归合并左右节点。
- 更新节点信息。
下面是参考代码。
1 | |
假设两个线段树的点集为
- 首先考虑共有的节点。显然需要
。 - 接下来考虑这些节点的子节点。显然最坏情况下一个共有节点有两个子节点都不是共有的,需要
的时间合并(直接接上去就行了)。总共是 。 - 如果一个节点的父节点并不是共有节点,显然它会在它的某个祖先节点合并时被合并。不需要额外计算复杂度。
因而总共的复杂度就是
线段树分裂
权值线段树也支持分裂。举个例子,加入要把权值线段树前
- 首先,考虑第
项在左节点还是右结点。 - 如果在左节点,那么就将右节点接到
的对应节点上,向左节点递归。 - 如果在右节点,那么就将左节点接到
的对应节点上,向右结点递归。
- 如果在左节点,那么就将右节点接到
参考代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25void split(ll rt, ll new_rt, ll dp) {
// 根节点 新的根节点 分割点
tree[new_rt] = tree[rt];
tree[new_rt].lc = -1;
tree[new_rt].rc = -1;
if (tree[rt].l == tree[rt].r) {
tree[new_rt].cnt = tree[rt].cnt - dp;
tree[rt].cnt = dp;
return;
}
if (tree[rt].lc != -1 && dp <= tree[tree[rt].lc].cnt) {
tree[new_rt].lc = new_node();
tree[new_rt].rc = tree[rt].rc;
tree[rt].rc = -1;
split(tree[rt].lc, tree[new_rt].lc, dp);
}
else {
tree[new_rt].rc = new_node();
split(tree[rt].rc, tree[new_rt].rc,
dp - (tree[rt].lc == -1 ? 0 : tree[tree[rt].lc].cnt));
}
update(rt);
update(new_rt);
return;
}